

Колись Інтернет був рішенням для об’єднання людей за допомогою комп’ютерів. Але сьогодні мережа об’єднує не лише мільярди користувачів, але й десятки мільярдів розумних пристроїв по всьому світу: від фітнес-трекерів та роботів-пилососів до промислових сенсорів. Цей новітній Інтернет речей (Internet of Things, IoT) генерує терабайти цінних даних, які дозволяють вирішувати найскладніші завдання: оптимізація процесів та операцій, ринкові та промислові дослідження, ухвалення рішень, створення нових бізнес-моделей тощо.
Як впоратися із цим потоком інформації? Давайте розберімось, як працює база даних для функціонування IoT: визначмо особливості та типові труднощі роботи з такими рішеннями. Ця стаття буде особливо корисною для розробників-початківців, аналітиків, менеджерів та керівників проєктів, які шукають шляхи оптимізації роботи з даними.
Що таке база даних для IoT пристроїв?
Будь-яка диджитал-система чи продукт потребує власної бази даних, або ж звертається до певних зовнішніх data-банків. Рішення для Інтернету речей не є виключенням. База даних для IoT - це спеціалізоване сховище, призначене для збору, зберігання та обробки великих інформаційних масивів, які генеруються пристроями Інтернету речей. Генеровані дані можуть бути дуже різноманітними: від показників температури та рівнів вологості до даних про рух і положення об'єктів.
-
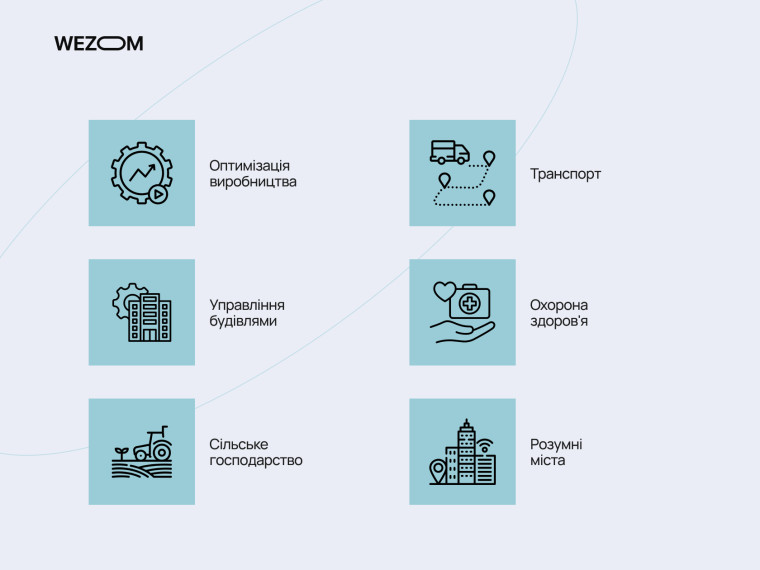
Оптимізація виробництва: Моніторинг стану обладнання, прогнозування збоїв, оптимізація енергоспоживання.
-
Управління будівлями: Контроль температури, освітлення, безпеки, енергоефективність.
-
Сільське господарство: Моніторинг стану полів, автоматизація поливу, прогнозування врожаю.
-
Транспорт: Відстеження транспортних засобів, оптимізація маршрутів, управління автопарком.
-
Охорона здоров'я: Моніторинг здоров'я пацієнтів, дистанційна діагностика, персоналізована медицина.
-
Розумні міста: Управління міською інфраструктурою, транспортними потоками, енергоспоживанням.
З погляду функціоналу така інформаційна база має забезпечувати низку можливостей:
-
Збір даних з різних джерел (пристрої, API);
-
Зберігання та організація даних у зручному для пошуку форматі;
-
Обробка даних: їх фільтрація, агрегація, аналіз тощо;
-
Візуалізація даних, тобто їх представлення у наочному та зрозумілому вигляді;
-
Інтеграція даних для взаємодії з різноманітними системами та додатками.
Технічно бази даних IoT можуть бути реалізовані у різні способи. Для інтернету речей застосовуються:
-
звичні реляційні бази даних (MySQL, PostgreSQL);
-
NoSQL-бази (MongoDB, Cassandra, HBase);
-
хмарні бази (Amazon DynamoDB, Google Cloud Bigtable);
-
Time-series бази даних (InfluxDB, TimescaleDB) тощо.
Рішення Інтернету речей незліченні: вони створюються під різні завдання та масштаби, відтак диктують різні вимоги щодо швидкодії, оновлення в реальному часі, безпеки, гнучкості тощо. Однак база даних завжди залишається одним з ключових компонентів інфраструктури IoT та фундаментом її ефективної роботи.
Особливості роботи з даними IoT
Побудова та підтримка бази даних для інтернету речей має власні підводні камені. Розробникам доведеться зважати на низку особливостей:
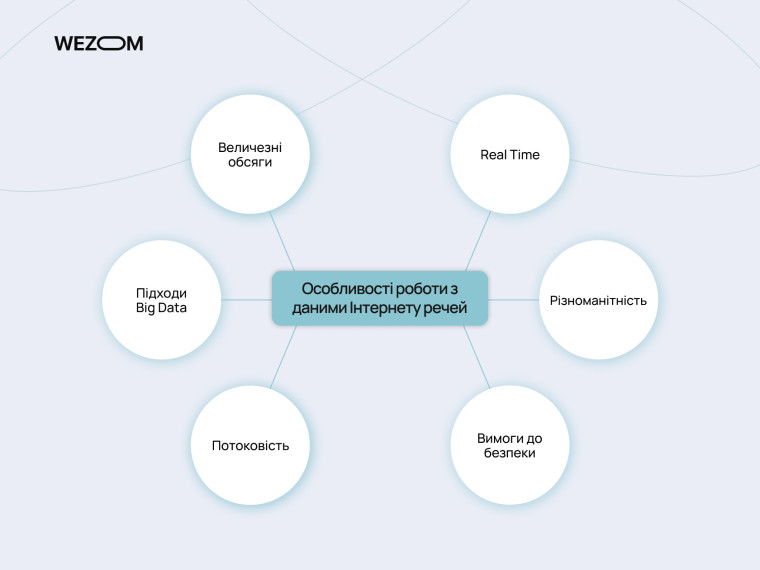
- Величезні обсяги даних
Масштабні IoT-системи зазвичай генерують величезні обсяги даних, оскільки охоплюють незліченну кількість підключених пристроїв. Дані з них можуть надходити безперервно, у потоковому режимі. Відтак важливо мати систему, що зможе впоратись із цим неймовірним інформаційним масивом. Важливо продумати ефективні методи зберігання та обробки даних IoT у хмарних або локальних системах. Бази даних мають бути надійними та придатними для горизонтального масштабування.
- Робота в реальному часі
У складних та критично важливих IoT-системах дані від пристроїв мають оброблятися без затримок, оскільки від швидкості реакції безпосередньо залежить перебіг операцій чи робота автоматики (наприклад, при виявленні несправностей або надзвичайних пригод). Для реалізації такої миттєвої роботи розробники нерідко вдаються до використання граничних обчислень, спеціалізованих легких протоколів та стримінгових платформ, таких як Apache Kafka або AWS Kinesis.
- Різноманітність даних
Дані з IoT-пристроїв дуже часто мають гетерогенну природу: вони можуть мати різні формати (структуровані, напівструктуровані, неструктуровані), різну частоту надходження та вимоги до обробки. Як приклад, це може бути інформація з сенсорів (температура, вологість), відео та аудіопотоки, текстові вводи тощо. Відтак інформаційна база має розв'язувати проблеми форматування, стандартизації та нормалізації даних, аби забезпечити сумісність між різними системами, пристроями та платформами.
- Безпека та конфіденційність даних
Дані у системах IoT можуть бути вкрай чутливими. Втручання у ці відомості може спричиняти дуже серйозні наслідки для будь-яких галузей: виробництво, охорона здоров’я, ланцюжки постачання тощо. Відтак база даних для системи інтернету речей має покладатись на надійні алгоритми шифрування та просунуті системи контролю доступу. Понад те, вона має відповідати міжнародним та локальним регулятивним вимогам захисту даних, таким як GDPR.
- Керування потоками даних
Оскільки потоки даних з багатьох IoT-пристроїв в системі можуть бути дуже об’ємними, інформаційна база потребує ефективних механізмів фільтрації та агрегування. Такі рішення допомагають зменшити обсяг даних для подальшого аналізу або зберігання. Використання в базі черг повідомлень і систем буферизації також допомагає управляти безперервним потоком даних, забезпечуючи баланс між пропускною здатністю мережі та швидкістю обробки.
- Зберігання даних
Робота з IoT будується на принципах та технологіях Big Data. Для зберігання та обробки величезних обсягів даних використовують розподілені системи зберігання, такі як Hadoop, Apache Cassandra, або Amazon S3. Ці рішення дозволяють масштабувати сховища даних відповідно до нагальних потреб. Необхідно також приділяти увагу архівуванню. Зберігання історичних даних важливе для подальшого аналізу трендів, стратегічного прогнозування, звітності тощо. Понад те, переміщення даних в архів допомагає звільнити ресурси для нових потоків.

Робота з даними IoT: типові виклики та труднощі
Обробка величезного інформаційного потоку в реальному часі може створювати суттєві виклики навіть для досвідчених фахівців. Розгляньмо основні труднощі, що можуть виникати при зберіганні та роботі з даними для IoT пристроїв.
- Великі масштаби
Системи Інтернету речей можуть генерувати величезні обсяги даних щоденно, а інколи навіть щогодинно. Фахівці мають вчасно і точно прогнозувати зростання навантаження на систему, аби адаптувати її та забезпечити продуктивність. База даних для IoT пристроїв має бути масштабованою та гнучкою. Поруч з тим виникає і проблема вартості. Великі обсяги даних потребують значних інвестицій у сховища, особливо якщо інформація треба зберігати тривалий час – для потреб бізнесу, аналітики, за вимогами регуляторних актів тощо.
- Гетерогенність
Data-база Інтернету речей може працювати з десятками тисяч різноманітних пристроїв та концентрувати у собі цілком різні типи даних. Відтак сховище має підтримувати роботу з різноманітними форматами інформації, що ускладнює її зберігання та обробку. Серйозним викликом у таких системах може стати консолідація: необхідність об'єднання та нормалізації даних із різних джерел в одній базі. Фахівцям нерідко доводиться наводити мости між цілком різними протоколами та форматами, вдаючись до специфічних технологій та інструментів.
- Темпи реального часу
IoT-пристрої найчастіше передають дані у режимі реального часу, що вимагає ефективних протоколів передачі та зберігання інформації. У деяких галузях існує обладнання, що генерує дані безперервно (наприклад, сенсори у виробництві, медичні сканери, системи спостереження), що диктує високі вимоги до швидкості зберігання та можливостей сховища. Система має бути готовою працювати з високою пропускною здатністю і мінімальними затримками – навіть під великими навантаженнями, із надмірною кількістю одночасних запитів.
- Виклики кіберзахисту
Платформи Інтернету речей можуть містити дуже чутливу інформацію: медичні та персональні відомості, критично важлива інформація про бізнес-процеси тощо. Відтак база даних для функціонування IoT потребує додаткових ресурсів та уваги до кібербезпеки. Дані Інтернету речей необхідно шифрувати при передачі та зберіганні, що ускладнює процес обробки. Понад те, операції з даними IoT потребують комплаєнсу: вони обов’язково мають відповідати національному законодавству та міжнародним вимогам захисту даних, таким як GDPR, ISO/IEC 27001 тощо.

- Питання надійності та бекапу
Втрата даних IoT у разі збою, аварії чи кібератаки може спричинити дуже суттєві наслідки, особливо у критично важливих галузях на кшталт виробництва чи медицини. Аби уникнути подібних ризиків, кожна data-база Інтернету речей потребує резервних копій та систем відновлення даних. Створення та регулярне оновлення бекапів системи вимагає суттєвих додаткових ресурсів і планування, адже йдеться про аварійне резервування дуже великих обсягів даних.
- Проблеми потокової обробки
Дані з IoT пристроїв дуже часто схожі на безперервну інформаційну течію, що потребує одночасної обробки та зберігання в режимі реального часу. Це створює додаткові вимоги до сховища, яке має забезпечити високу пропускну здатність. Аби уникнути втрати даних чи зниження продуктивності, фахівці вдаються до інструментів на кшталт буферизації та граничних обчислень. Якщо база даних або мережа недоступні, буфер дозволяє тимчасово зберігати, чи навіть попередньо обробляти інформацію до відновлення нормальної роботи.
Оптимізація обробки та зберігання даних IoT пристроїв
Як врахувати особливості роботи з базами даних для IoT та уникнути типових проблем? Розгляньмо основні шляхи оптимізації, що допомагають налагодити інформаційний обмін в системі Інтернету речей.
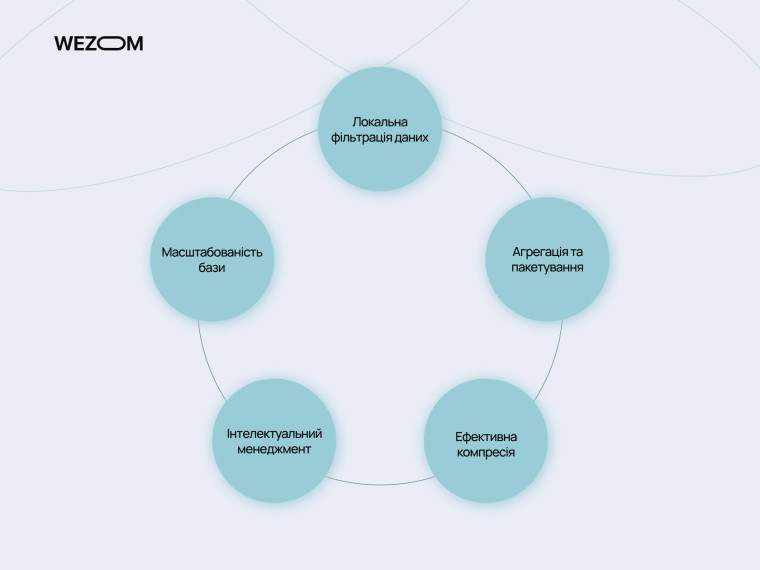
Фільтрація даних на пристрої
Одне з ключових завдань налагодження екосистеми IoT полягає в тому, аби знизити навантаження на центральну базу даних. Найкращою практикою для цього нині стала децентралізація: впровадження граничних (edge computing) та “туманних” (fog computing) обчислень.
Зміст цих підходів полягає в тому, аби частково чи повністю перенести обробку, фільтрацію та аналіз даних якомога ближче до джерела їх походження. Так, сенсор IoT буде спершу скеровувати свої покази не на центральний сервер, а на локальний обчислювальний вузол. Алгоритм у цьому вузлі може вирішувати, чи варті нові дані передачі у центральний сервер для подальшої обробки (наприклад, чи виходять показники сенсора за допустимі межі).
Локальна фільтрація та агрегація даних дозволяє відсіювати нерелевантні та непотрібні для центральної системи відомості, а відтак – скорочувати навантаження на мережу та базу даних. Понад те, децентралізація забезпечує системі запас міцності: окремі вузли можуть продовжувати операції навіть у випадку відмови центрального сервера чи сховища даних.
Агрегація даних
Ще один шлях до зменшення навантаження на систему криється у зменшенні частоти запису: передача не обов'язково має здійснюватись в режимі реального часу. Замість того, аби зберігати кожне окреме значення від пристрою, дані можна агрегувати за певними проміжками часу (хвилини, години, дні) – відповідно до вимог операцій та галузі, в якій працює мережа IoT. Це дозволяє зберігати лише середні, мінімальні, максимальні або сумарні значення. Понад те, агрегація дозволяє збирати та об'єднувати дані з кількох пристроїв, що також знижує частоту передач і оптимізує використання мережевих ресурсів.
Аби мінімізувати навантаження на систему без втрати продуктивності, агреговані дані можна передавати на сервер пакетами, що формуються протягом певного часу. Цей підхід може бути особливо корисним для пристроїв з обмеженими ресурсами, такими як сенсори. Під час формування пакета для центральної бази інформація може проходити через локальну фільтрацію та обробку, що додатково підвищує ефективність усієї архітектури.
Компресія даних
Варто також приділити увагу тому, в якому вигляді дані передаються у централізоване сховище. Ефективна компресія дозволяє заощадити трафік, прискорити швидкість передачі та мінімізувати ймовірність втрати даних під час передачі, підвищуючи надійність системи. Застосування алгоритмів стиснення (gzip, zlib) перед передачею даних з IoT пристроїв допомагає зменшити обсяг передавання, що позитивно впливає на пропускну здатність та стабільність системи.

Понад те, компресія вкрай корисна і при довготривалому зберіганні інформації. Деякі бази даних (наприклад, TimescaleDB, InfluxDB) підтримують автоматичне стиснення даних при зберіганні, що зменшує їх обсяг без втрати суттєвого змісту. Це може бути особливо корисним при архівуванні, резервному копіюванні даних тощо.
Однак варто пам’ятати, що компресія/декомпресія з високим ступенем стиснення потребує суттєвих обчислювальних ресурсів. Це особливо критично для систем реального часу, які в певних сценаріях можуть потребувати швидкісної декомпресії архівів.
Інтелектуальне керування життєвим циклом даних
Спеціалізовані практики та інструменти управління даними дозволяють оптимізувати їхнє зберігання, обробку та застосування. Життєвий цикл кожного байту інформації у системі можна зробити економічно ефективним, прозорим та безпечним.
Зокрема, історичні дані, які більше не потрібні у швидкому доступі чи аналітиці, можуть бути переміщені в архіви або холодне сховище (cold storage). Це знижує витрати на зберігання та звільняє максимум ресурсів для роботи з актуальними даними.
Наступним кроком може бути автоматизоване видалення історичних та архівних даних, які не несуть жодної цінності для бізнесу. Це важливо не лише з огляду на економію коштів та ресурсів системи, але й з огляду кібербезпеки. Адже навіть неактуальні дані можуть становити певну цінність для злочинців, які шукають будь-які заціпки та вразливості у системах організації.
Масштабованість баз даних
Обсяг та різноманітність даних, які генеруються пристроями інтернету речей, зростають експоненційно. Відтак будь-яка база даних для IoT систем має бути масштабованою: бути готовою до величезних інформаційних потоків, підтримувати високу пропускну здатність, легко включати у себе нові вузли, залишатись стабільною й доступною в будь-яких сценаріях.
Для IoT-систем, які генерують великі обсяги даних, варто використовувати data-бази з широкими можливостями горизонтального масштабування. Йдеться про можливість легко включати в архітектуру нові сервери для розподілу навантаження (наприклад, Cassandra, HBase).
Важливими для масштабування також є механізми шардінгу, тобто розбиття даних на частини для розподілу між різними серверами. Це допомагає розвантажити окремі вузли системи та забезпечити ефективну обробку великих обсягів даних. Використання розподілених систем, таких як MongoDB, дозволяє обробляти дані на кількох серверах одночасно, забезпечуючи швидкість та надійність.

Відкрийте можливості з розробкою IoT рішень з нашою командою професіоналів.
Розробка рішень IoT з командою WEZOM
Ми вже понад 25 років створюємо кастомні диджитал-рішення для бізнесу: CRM та ERP-системи, корпоративне ПЗ, мобільні та веб-додатки будь-якої складності, засоби автоматизації та роботизації бізнесу. Нам довіряють провідні українські та світові компанії з таких сфер як eCommerce, виробництво, логістика, охорона здоров’я, енергетика тощо.
Відтак ми добре розуміємо, як працює IoT система та база даних для неї, і готові будувати такі рішення з нуля. В одному з наших нещодавніх кейсів ми реалізували масштабну ERP-систему та білінгову CMS для великого енергетичного холдингу. Робота над цим проєктом потребувала створення надійних та безпечних баз даних, що оновлюються в реальному часі.
Якщо вас цікавлять можливості впровадження таких технологій у бізнес, не шукайте відповіді самотужки. Звертайтеся по консультацію до наших фахівців просто зараз: вони радо поділяться досвідом, підкажуть оптимальні рішення, зорієнтують у питаннях строків та вартості подібних проєктів. Всього один крок на зустріч диджиталу може повністю змінити усю вашу компанію, дозволить їй вирватися на новий рівень.

Висновки
Розробка баз даних для IoT – це комплексне завдання, яке вимагає глибоких знань в області баз даних, Big Data, хмарних технологій та граничних обчислень. Розробники, які працюють в цій царині, мають враховувати специфіку напрямку та усі можливі складнощі роботи з даними інтернету речей: великі масштаби та різноманітність, необхідність оперувати потоком даних в реальному часі, виклики кібербезпеки, надійності, швидкодії системи тощо.
Ми не рекомендуємо довіряти розробку або інтеграцію такої системи фахівцям без відповідного досвіду. Найкращим рішенням може стати звернення до зрілої IT-команди, що має за плечима відповідні кейси та міцну репутацію.


